עצים הם אחד ממבני הנתונים הידועים והחשובים בפיתוח קוד ובמדעי המחשב. הוא גם אחד הנושאים הגדולים ולא נוכל להעמיק בנושא הזה כראוי. ישנם סוגים שונים של עצים: ישנם סתם עצים, עצים בינרים, עצים מאוזנים, לא-מאוזנים, עצי BST ועוד.
גם כאשר מבינים מהו עץ ואיך הוא בנוי, יש צורך להבין איך סורקים אותו, מה שנקרא traverse וגם כאן יש סוגים שונים של סריקות - DFS או BFS.
בפוסט זה ננסה קצת לעשות סדר בנושא מורכב זה ובתקווה להצליח לסייע להוריד מעט מהסיבוך הכרוכים בלימוד הנושא.
כדי להבין מהו עץ, כדאי קודם להבין מהי רשימה מקושרת. אם הנושא לא מוכר לכם, אני ממליץ לכם לקרוא על הנושא קודם. תוכלו גם לקרוא את הפוסט שפרסמתי בנושא זה.
ההבדל המרכזי בין רשימה מקושרת לבין עץ הוא שכל איבר בעץ יכול להצביע אל יותר מאיבר אחד, למרות שאין זו חובה. במילים אחרות, רשימה מקושרת יכולה להיחשב מקרה פרטי של עץ.
היתרון והיעילות של העץ מתבטאים בדרך בה הערכים והאיברים מתפזרים על העץ. אחד מסוגי העץ הנפוצים הוא עץ בינארי והוא נקרא כך כיוון שלכל אחד מהאיברים שלו יש לפחות שני איברים הנקראים "בנים" והאיבר עצמו נקרא "אב" או "שורש" תלוי באיזה הקשר מתייחסים אליו.
מקובל לצייר את העצים ואת הערכים שלהם כדי לקבל מושג ברור יותר לגבי התכולה שלו. מתחילים מהשורש וממשיכים למטה לבנים וכן הלאה. למרות שזו הקונבציה, אין זו חובה וניתן לצייר את השורש למטה ואת הבנים מעליו - בכל מקרה בעץ אין מושג כזה של למטה או למעלה, אלא רק Node, Left Child, Right Child.

בעץ בינארי, לכל אחד מהאיברים (Node) יכול להיות בן ימני או בן שמאלי או שניהם - כאשר חוקיות זו ממשיכה הלאה ללא הגבלה של אורך. איבר יכול להיות ללא ילדים ואז הוא יקרא עלה (Leaf) - זה אומר שהגעתם לקצה "הענף" של העץ או שאתם מסתכלים על Node יחיד.
כאשר מקבלים הפנייה לעץ, נקבל את הכתובת של השורש של העץ (Root). הציפיה היא לקבל בכתובת זו את ה-Node הראשון של העץ כדי שיהיה אפשר להתחיל לקרוא אותו באמצעות Traverse - אך זו לא דרישה, כלומר - הכתובת מאחורי ה-Root יכולה להיות גם Null וזה מסמל לנו שמדובר בעץ ריק שאין בו כלום.
Traverse

כדי לקבל את הערכים של העץ יש לבצע עליו "מעבר" שמקובל לכנות כ-Traverse. בניגוד לרשימה מקושרת, שם המעבר היה פשוט, רק להמשיך הלאה עד שמגיעים לסוף הרשימה - כאן זה נראה יותר כמו מבוך שדורש חשיבה. אם ממשיכים בכיוון הלא נכון יכולים להגיע למבוי סתום.
בשיטה זו אנחנו נסרוק את העץ לעומקו: "נצלול" קודם לעומק ואז "ניסוג" לאחור תוך כדי שאנחנו עוברים על כל האיברים של העץ. כדי לממש את זה בקוד, לרוב משתמשים ברקורסיה, אך אפשרי גם לבצע זאת באמצעות לולאת While.
בשיטה זו אנחנו נסרוק את העץ לאורכו: נתחיל מהשורש ואז נעבור לרוחב על כל האיברים. במימוש הקוד, נשתמש ב-Queue כדי להגיע לאיברים בצורת LIFO - כלומר, האיבר האחרון הוא הראשון לצאת.
סריקה זו גם נקראת לפעמים Level Order Traversal.
כדי להכניס או להוריד ערך חדש לעץ קיים עם ערכים, נצטרך קודם להגיע לנקודת היעד בה אנו רוצים להכניס או להוריד את המספר ואז נוסיף אותו כבן ימני או שמאלי לאיבר שהגענו אליו או לחילופין, נסיר אותו ונמשיך את הקישור בין האיברים כמו שעשינו ברשימה מקושרת.
בעיקרון, אין הגבלה כלשהי בעצים איך לאחסן את הערכים - כלומר, אם נחליט סתם לפזר מספרים בצורה רנדומלית או לשים את כל המספרים בזה אחר זה, אין מניעה לכך בהגדרה של עץ.
זה כמובן יוצר בעיה, כיון שאז אנו עלולים לאבד את היתרון של העץ ולהפוך אותו בפועל לרשימה מקושרת כך שכשנרצה להגיע לאיבר האחרון בעץ, נצטרך לעבור את כל האיברים שלו.
לשם כך קיימים סוגים שונים של עצים עם הגבלות מיוחדות שמאפשרות להם לשמור על יעילות באחסון ובקריאה של ערכים.
BST: Binary Search Tree
בהרבה מקרים בהם נשמע על עצים בינארים, זה יהיה בהקשר של עצי BST. עצים אלה מנצלים את המבנה של העץ הבינארי כדי לאחסן בצורה יעילה מספרים כך שיהיה ניתן לערוך חיפוש ולמצוא אותם ביעילות של Log(n) בדומה לחיפוש בינארי על מערך ממוין.

Balanced vs. Non-Balanced Trees
עצי BST נראים לכאורה פתרון מושלם עבור אחסון וחיפוש יעיל, אך יש להם פגם בתכנון שמאפשר להם להיות לא יעילים.

כאשר מכניסים אל העץ ספרות ממויינות בסדר עולה או יורד מספר פעמים, זה יוצר בעץ ענפים ארוכים הגורמים לחיפוש להתארך - עד כדי, במקרה הגרוע ביותר ליעילות דומה של יעילות מקושרת.
במונחים של עצים, זה נקרא שהעץ אינו מאוזן (Balanced), כלומר - זה לא מספיק שהעץ יאחסן את הלוגיקה שלו ויקבל את הערכים המוזנים אליו באופן פאסיבי - אלא הוא צריך אקטיבית לדאוג לכך שהמבנה שלו יישמר כדי שמאוחר יותר החיפוש של הערכים יהיה יעיל, לא משנה אילו ערכים הזינו לו.
ישנם מספר דרכים לאזן את המבנה של העץ והמוכרת בהם נקראת AVL Tree.
AVL Tree
AVL הוא למעשה מימוש מתקדם יותר של BST Tree והוא נועד לפתור את הבעיה שציינו מקודם - חוסר איזון בעץ כתוצאה מהכנסת ערכים הגורמים ל-"ענפים" ארוכים במיוחד שבסופו של דבר יגרמו לאיטיות בחיפושים הבאים.
עץ מאוזן מוגדר כך שהמרחק בין הענף הקצר ביותר לארוך ביותר אינו עולה על 1. תהליך האיזון נשמר תוך כדי הכנסת הערכים אל העץ (ומחיקתם) ועל ידי ביצוע תהליך מורכב יחסית הנקרא Rotation.
כדאי לראות ויזואליזציה של עץ AVL כדי להבין קודם במה מדובר, למשל כאן.
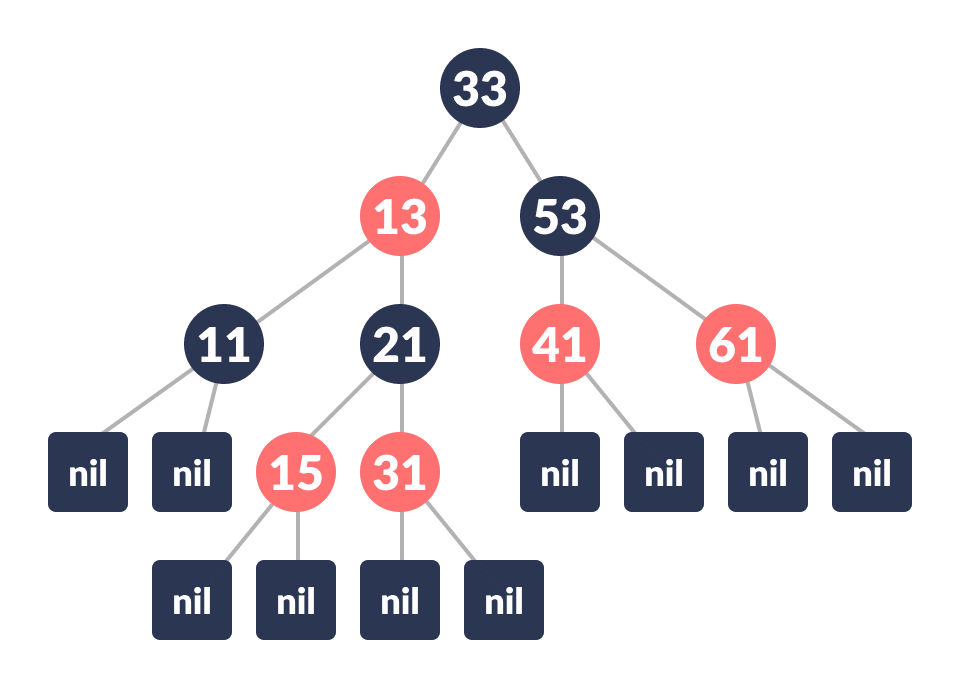
Red/Black Tree
עץ R/B הוא עץ BST שבדומה ל-AVL מאזן את עצמו, אך בצורה שונה ועל פי הכללים הבאים:
- כל Node בעץ הוא שחור או אדום.
- השורש תמיד שחור.
- העלים תמיד שחורים.
- כל Node שיש לו ילדים - הוא אדום והילדים הם בצבע שחור.
- מספר ה-Nodes השחורים מהשורש עד לאותו Node נקראים black depth של אותו Node.
B-Tree
עץ זה הוא לא בינארי אבל עיקרון הבנייה שלו דומה ל-BST. בעץ זה ניתן לאחסן כמות גדולה יותר מ-2 ילדים לכל Node, בהתאם להגדרה של העץ. המטרה של עץ זה היא להקל על חיפוש הערכים בשכבות הנמוכות על ידי יצירת מעין אינדקס בשכבות העליונות של העץ.
הוא שימושי במיוחד עבור תוכנות שיש להם מספר גדול של נתונים שיש למצוא אותם במהירות גבוהה יחסית כמו למשל - Databases.
כל העלים נדרשים להיות באותה רמה. לכל Node יש מספר מינימלי ומקסימלי של ילדים שמותר לו להחזיק מלבד השורש שמותר לו להחזיק רק Node יחיד.
בניגוד לעץ בינארי, עץ B-Tree גדל לרוחב ולא לעומק.
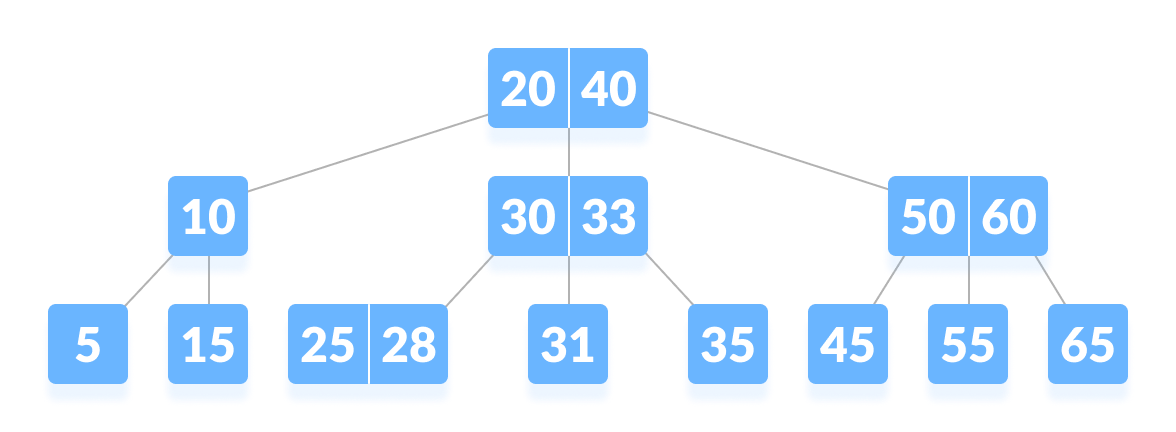
ויזואליזציה של עץ B-Tree.
+ B-Tree
מימוש מתקדם יותר של B-Tree עם הבדל מרכזי: המידע מאוחסן רק ברמת העלים (הרמה התחתונה) והעלים מקושרים ביניהם באופן דו-כיווני כדי להקל את הקריאה שלהם.
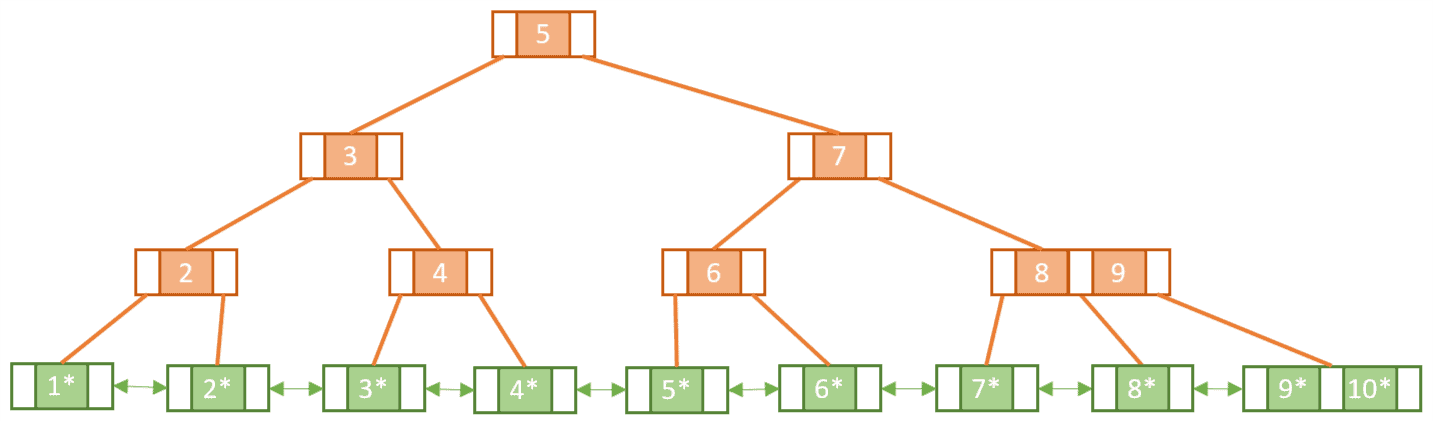
ויזואליזציה של עץ +B-Tree.
סיכום
ישנם עוד הרבה סוגים של עצים, אבל עברנו על הידועים שבהם ובאלה שככל הנראה שתיתקלו בהם בזמן הלימודים. בראיונות עבודה, לרוב שואלים על BST כיון שקל יחסית להסביר את המבנה שלו ורוב הסיכויים שהמועמד שמע עליו ולכן, רוב הבעיות משתמשות בו.
אין תגובות:
הוסף רשומת תגובה